Are you guys just generating insanely difficult code? I feel like 90% of all my code generation with o1 works first time? And if it doesn’t, I just let GPT know and it fixes it right then and there?
the problem is more complex than initially thought, for a few reasons.
One, the user is not very good at prompting, and will often fight with the prompt to get what they want.
Two, often times the user has a very specific vision in mind, which the AI obviously doesn’t know, so the user ends up fighting that.
Three, the AI is not omnisicient, and just fucks shit up, makes goofy mistakes sometimes. Version assumptions, code compat errors, just weird implementations of shit, the kind of stuff you would expect AI to do that’s going to make it harder to manage code after the fact.
unless you’re using AI strictly to write isolated scripts in one particular language, ai is going to fight you at least some of the time.
I asked an LLM to generate tests for a 10 line function with two arguments, no if branches, and only one library function call. It’s just a for loop and some math. Somehow it invented arguments, and the ones that actually ran didn’t even pass. It made like 5 test functions, spat out paragraphs explaining nonsense, and it still didn’t work.
This was one of the smaller deepseek models, so perhaps a fancier model would do better.
I’m still messing with it, so maybe I’ll find some tasks it’s good at.
from what i understand the “preview” models are quite handicapped, usually the benchmark is the full fat model for that reason. the recent openAI one (they have stupid names idk what is what anymore) had a similar problem.
If it’s not a preview model, it’s possible a bigger model would help, but usually prompt engineering is going to be more useful. AI is really quick to get confused sometimes.
My first attempt at coding with chatGPT was asking about saving information to a file with python. I wanted to know what libraries were available and the syntax to use them.
It gave me a three page write up about how to write a library myself, in python. Only it had an error on damn near every line, so I still had to go Google the actual libraries and their syntax and slosh through documentation
I just generated an entire angular component (table with filters, data services, using in house software patterns and components, based off of existing work) using copilot for work yesterday. It didn’t work at first, but I’m a good enough software engineer that I iterated on the issues, discarding bad edits and referencing specific examples from the extant codebase and got copilot to fix it. 3-4 days of work (if you were already familiar with the existing way of doing things) done in about 3-4 hours. But if you didn’t know what was going on and how to fix it you’d end up with an unmaintainable non functional mess, full of bugs we have specific fixes in place to avoid but copilot doesn’t care about because it doesn’t have an idea of how software actually works, just what it should look like. So for anything novel or complex you have to feed it an example, then verify it didn’t skip steps or forget to include something it didn’t understand/predict, or make up a library/function call. So you have to know enough about the software you’re making to point that stuff out, because just feeding whatever error pops out of your compiler may get you to working code, but it won’t ensure quality code, maintainability, or intelligibility.


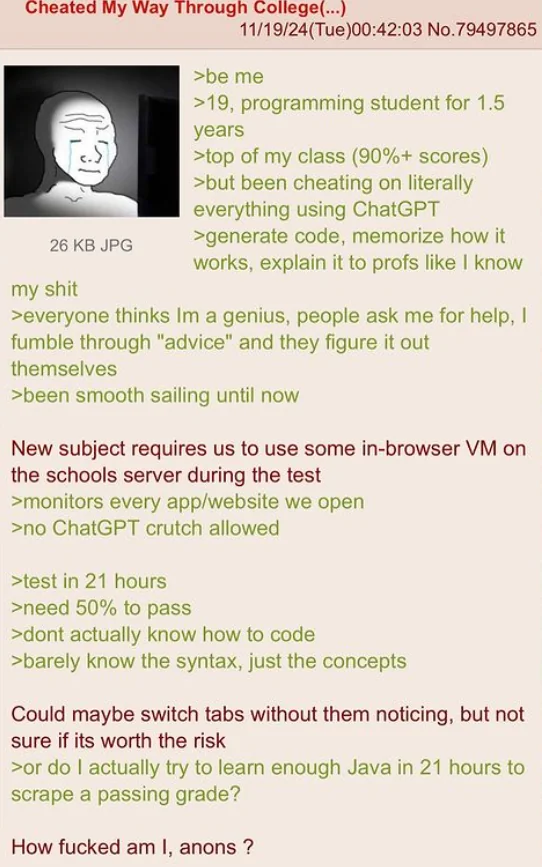{kind=link}
Are you guys just generating insanely difficult code? I feel like 90% of all my code generation with o1 works first time? And if it doesn’t, I just let GPT know and it fixes it right then and there?
the problem is more complex than initially thought, for a few reasons.
One, the user is not very good at prompting, and will often fight with the prompt to get what they want.
Two, often times the user has a very specific vision in mind, which the AI obviously doesn’t know, so the user ends up fighting that.
Three, the AI is not omnisicient, and just fucks shit up, makes goofy mistakes sometimes. Version assumptions, code compat errors, just weird implementations of shit, the kind of stuff you would expect AI to do that’s going to make it harder to manage code after the fact.
unless you’re using AI strictly to write isolated scripts in one particular language, ai is going to fight you at least some of the time.
I asked an LLM to generate tests for a 10 line function with two arguments, no if branches, and only one library function call. It’s just a for loop and some math. Somehow it invented arguments, and the ones that actually ran didn’t even pass. It made like 5 test functions, spat out paragraphs explaining nonsense, and it still didn’t work.
This was one of the smaller deepseek models, so perhaps a fancier model would do better.
I’m still messing with it, so maybe I’ll find some tasks it’s good at.
from what i understand the “preview” models are quite handicapped, usually the benchmark is the full fat model for that reason. the recent openAI one (they have stupid names idk what is what anymore) had a similar problem.
If it’s not a preview model, it’s possible a bigger model would help, but usually prompt engineering is going to be more useful. AI is really quick to get confused sometimes.
It might be, idk, my coworker set it up. It’s definitely a distilled model though. I did hope it would do a better job on such a small input though.
Can not confirm. LLMs generate garbage for me, i never use it.
My first attempt at coding with chatGPT was asking about saving information to a file with python. I wanted to know what libraries were available and the syntax to use them.
It gave me a three page write up about how to write a library myself, in python. Only it had an error on damn near every line, so I still had to go Google the actual libraries and their syntax and slosh through documentation
I just generated an entire angular component (table with filters, data services, using in house software patterns and components, based off of existing work) using copilot for work yesterday. It didn’t work at first, but I’m a good enough software engineer that I iterated on the issues, discarding bad edits and referencing specific examples from the extant codebase and got copilot to fix it. 3-4 days of work (if you were already familiar with the existing way of doing things) done in about 3-4 hours. But if you didn’t know what was going on and how to fix it you’d end up with an unmaintainable non functional mess, full of bugs we have specific fixes in place to avoid but copilot doesn’t care about because it doesn’t have an idea of how software actually works, just what it should look like. So for anything novel or complex you have to feed it an example, then verify it didn’t skip steps or forget to include something it didn’t understand/predict, or make up a library/function call. So you have to know enough about the software you’re making to point that stuff out, because just feeding whatever error pops out of your compiler may get you to working code, but it won’t ensure quality code, maintainability, or intelligibility.
A lot of people assume their not knowing how to prompt is a failure of the AI. Or they tried it years ago, and assume it’s still as bad as it was.
Garbage for me too except for basic beginners questions